PerAnsSumm Shared Task - CL4Health@ NAACL 2025
👋 Welcome to the official shared task website for PerAnsSumm: Perspective-aware Healthcare answer summarization, a shared task organized at the CL4Health workshop colocated with NAACL 2025.
Introduction
In recent years, healthcare community question-answering (CQA) forums have gained popularity, allowing users to seek advice by posting healthcare-related questions and receiving answers from other users. These answers provide an array of user perspectives, ranging from sharing personal experiences to providing factual information or offering suggestions. Traditionally, the CQA answer summarization task focuses on a single best-voted answer [1, 2] as a reference summary. However, a single answer often fails to capture the diverse perspectives presented across multiple answers. Providing the answers in structured, perspective-specific summaries could better serve the information needs of end users
The PerAnsSumm shared task focuses on identifying and classifying perspective-specific spans (Task A) and generating perspective-specific summaries from the question-answer thread (Task B).
Task Description
Given a question Q, a set of answers A, and perspective categories (‘cause’, ‘suggestion’, ‘experience’, ‘question’, and ‘information’), you are assigned the following two tasks:
- Task A: Identify the spans in the user answers that reflect a particular perspective and classify the span to the correct perspective.
- Task B: Generate a concise summary that represents the underlying perspective contained within the spans across all answers.
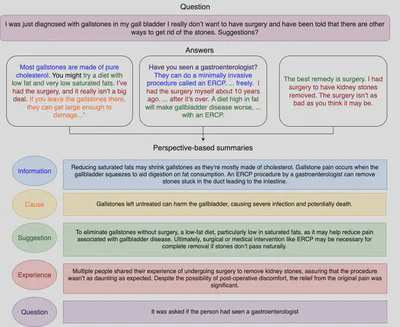
Dataset
We use the PUMA dataset [3], a perspective-aware summary annotated corpus of medical question-answer pairs. The PUMA dataset consists of 3, 167 CQA threads with approximately 10K answers filtered from the Yahoo! L6 corpus. Each answer in PUMA is annotated with five perspective spans: ‘cause’, ‘suggestion’, ‘experience’, ‘question’, and ‘information’. Following the perspective and span annotations, summaries are written for each identified perspective. These summaries are concise representations of the underlying perspectives contained within the spans across all answers. Each CQA thread has up to five perspective-specific summaries.
Participation
Please visit the CodaBench page to register for the competition and access the dataset.
Submission guidelines are available in the here.
Evaluation Metrics
For each subtask, we will evaluate submissions based on the below mentioned automatic metrics.
For Task A (Span Identification and Classification), we will evaluate using (i) macro-averaged F1 score for classification and (ii) Strict-matching and Proportional-matching for Span Identification.
For Task B (Summary Generation), we will evaluate generated summaries across two aspects: (i) relevance and (ii) factuality. Each of these evaluation aspect is composed of multiple automatic metrics.
- Relevance - ROUGE (R1, R2, and RL) [4], BLEU [5], Meteor [6], and BERTScore [7]
- Factuality - AlignScore [8] and SummaC [9]
The scores presented for these metrics will be macro-averaged (wherever applicable) across all 5 perspective labels. The aim of this maximize the scores for these automatic metrics.
We will rank submissions based on each of these metrics independently. The final ranking (after the evalutation phase is over) will include normalisation of the scores and human evaluation of the generated summaries. A ranking for task-wise performance will be released along with an overall ranking based on the average of the two tasks.
Timeline
First call for participation: 12th November, 2024
Release of task data (training, validation): 12th November, 2024
Release of test data: 25th January, 2025
Results submission deadline: 4th February, 2025
Release of final results: 5th February, 2025
System papers due: 25th February, 2025
Notification of acceptance: 4th March, 2025
Camera-ready papers due: 10th March, 2025
CL4Health Workshop: TBC
* All deadlines are 23:59 UTC-12 (“anywhere on Earth”).
Leaderboard
The Official Task Leaderboard is available here
The official leaderboard will be updated twice a day - 12:00 PM CST (submissions received before 9 AM CST) and 12:00 AM CST (submissions received before 9 PM CST).Cash Prize
We will award the following prizes to participants:
- First Prize: USD $100
- Second Prize: USD $50
Please note that in order to be eligible for the cash prize, you must participate in both tasks and submit a system paper.
System Paper Submission
All participating teams are invited to submit system papers that, pending review, will be published as part of the CL4Health Workshop proceedings and indexed in the ACL Anthology.
Submissions must be electronic and in PDF format, using the Softconf START conference management system.
The submission site is: https://softconf.com/naacl2025/cl4health2025
Please select the submission category as “shared task”.
Submission Deadline: 2.25.2025 11:59 PM AoE (Anywhere on Earth)
Format
System papers should follow the ACL 2025 paper format (up to 8 pages, with unlimited pages for appendices and references). ACL provides style files for LaTeX and Microsoft Word at https://github.com/acl-org/acl-style-files.
The optional limitations and ethical considerations sections, references, and appendices should be included in the PDF for the paper (not counting towards the page limit), and not be submitted as a separate PDF.
Paper titles should adopt the format: “{TEAM_NAME} at PerAnsSumm 2025:” followed by a descriptive title of the proposed approach. Papers should be submitted in a non-anonymised format (i.e., with author names included).
References
PerAnsSumm 2025 Overview Paper - the following citation should be used when referring to the shared task in general (note, this is a temporary example that may be subject to change in the future):
@inproceedings{peransumm-overview,
title = Overview of the PerAnsSumm 2025 Shared Task on Perspective-aware Healthcare Answer Summarization",
author = "Agarwal, Siddhant and
Akhtar, Md Shad and
Yadav, Shweta",
booktitle = "Proceedings of the Second Workshop on Patient-Oriented Language Processing (CL4Health) @ NAACL 2025",
month = May,
year = "2025",
address = "Albuquerque, USA",
publisher = "Association for Computational Linguistics"
}
Task datasets - the following citation should be used when referring to the task dataset:
@inproceedings{naik-etal-2024-perspective,
title = "No perspective, no perception!! Perspective-aware Healthcare Answer Summarization",
author = "Naik, Gauri and
Chandakacherla, Sharad and
Yadav, Shweta and
Akhtar, Md Shad",
editor = "Ku, Lun-Wei and
Martins, Andre and
Srikumar, Vivek",
booktitle = "Findings of the Association for Computational Linguistics: ACL 2024",
month = aug,
year = "2024",
address = "Bangkok, Thailand",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2024.findings-acl.942/",
doi = "10.18653/v1/2024.findings-acl.942",
pages = "15919--15932"
}
Reviewer Nomination
Similar to other shared task campaigns (e.g. SemEval), we are requiring that at least one author per paper also acts as a reviewer for our shared task papers. Please nominate the reviewer from your submission using this form. If you do not nominate a reviewer, the corresponding author(s) will be automatically selected.
FAQs:
- I ranked <X> on the leaderboard, am I eligible to submit a system paper? Yes, All participating teams are invited to submit a system paper irrespective of rank.
- How does a system paper work? What am I supposed to write? Please look at system paper submissions from other shared tasks such as BioLaySumm. We follow a standard submission format similar to those. Some examples are available here - https://aclanthology.org/2024.bionlp-1.73.pdf, https://aclanthology.org/2024.bionlp-1.77.pdf, https://arxiv.org/pdf/2405.11950
- I am unable to submit the paper by the deadline, can it be extended? No. The submission deadline will not be extended due to time constraints.
Organizers
- Shweta Yadav - University of Illinois at Chicago, USA
- Md. Shad Akhtar - Indraprastha Institute of Information Technology Delhi, India
- Siddhant Agarwal - University of Illinois at Chicago, USA
References
[1] Tanya Chowdhury and Tanmoy Chakraborty. Cqasumm: Building references for community question answering summarization corpora. In Proceedings of the ACM india joint international conference on data science and management of data, pages 18–26, 2019.
[2] Tanya Chowdhury, Sachin Kumar, and Tanmoy Chakraborty. Neural abstractive summarization with structural attention. arXiv preprint arXiv:2004.09739, 2020.
[3] Gauri Naik, Sharad Chandakacherla, Shweta Yadav,and Md Shad Akhtar. No perspective, no perception!! perspective-aware healthcare answer summarization. In Lun-Wei Ku, Andre Martins, and Vivek Srikumar, editors, Findings of the Asso- ciation for Computational Linguistics ACL 2024, pages 15919–15932, Bangkok, Thailand and virtual meeting, August 2024. Association for Computational Linguistics.
[4] Chin-Yew Lin. ROUGE: A package for automatic evaluation of summaries. In Text Summarization Branches Out, pages 74–81, Barcelona, Spain, July 2004. Association for Computational Linguistics.
[5] Kishore Papineni, Salim Roukos, Todd Ward, and Wei-Jing Zhu. Bleu: a method for automatic evaluation of machine translation. In Pierre Isabelle, Eugene Charniak, and Dekang Lin, editors, Proceedings of the 40th Annual Meeting of the Association for Computational Linguistics, pages 311–318, Philadelphia, Pennsylvania, USA, July 2002. Association for Computational Linguistics.
[6] Satanjeev Banerjee and Alon Lavie. METEOR: An automatic metric for MT evaluation with improved correlation with human judgments. In Jade Goldstein, Alon Lavie, Chin-Yew Lin, and Clare Voss, editors, Proceedings of the ACL Workshop on Intrinsic and Extrinsic Evaluation Measures for Machine Translation and/or Summarization, pages 65–72, Ann Arbor, Michigan, June 2005. Association for Computational Linguistics.
[7] Tianyi Zhang, Varsha Kishore, Felix Wu, Kilian Q. Weinberger, and Yoav Artzi. Bertscore: Evaluating text generation with bert. In International Conference on Learning Representations, 2020.
[8] Yuheng Zha, Yichi Yang, Ruichen Li, and Zhiting Hu. Alignscore: Evaluating factual consistency with a unified alignment function. In Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 11328–11348, 2023.
[9] Philippe Laban, Tobias Schnabel, Paul Bennett, and Marti A Hearst. Summac: Re-visiting nli-based models for inconsistency detection in summarization. Transactions of the Association for Computational Linguistics, 10:163–177, 2022.